Multi-view Deep Learning Improves Detection of Major Cardiac Conditions from Echocardiography
Biomedical imaging captures complex three-dimensional (3D) anatomic structures with multiple two-dimensional (2D) views or projections. Across various medical imaging modalities, single views capture only partial information about 3D structures, requiring clinicians or scientists to mentally integrate complementary perspectives to form a coherent understanding of 3D structure, anatomic motion, and function.
Most existing deep learning models operate on a single input image or video at a time. They are not designed to jointly reason across multiple complementary views. Our work was motivated by the desire to enable deep learning models to explicitly integrate multiple complementary imaging views in a single predictive framework, mirroring how human experts interpret medical imaging studies.
We developed a novel multi-view neural network architecture
We developed a multi-view deep neural network architecture designed to integrate multiple imaging videos (views) simultaneously. The framework extends video-based deep learning models by introducing dedicated cross-view convolutional blocks, allowing the neural network to learn both within-view and across-view spatiotemporal features and relationships.
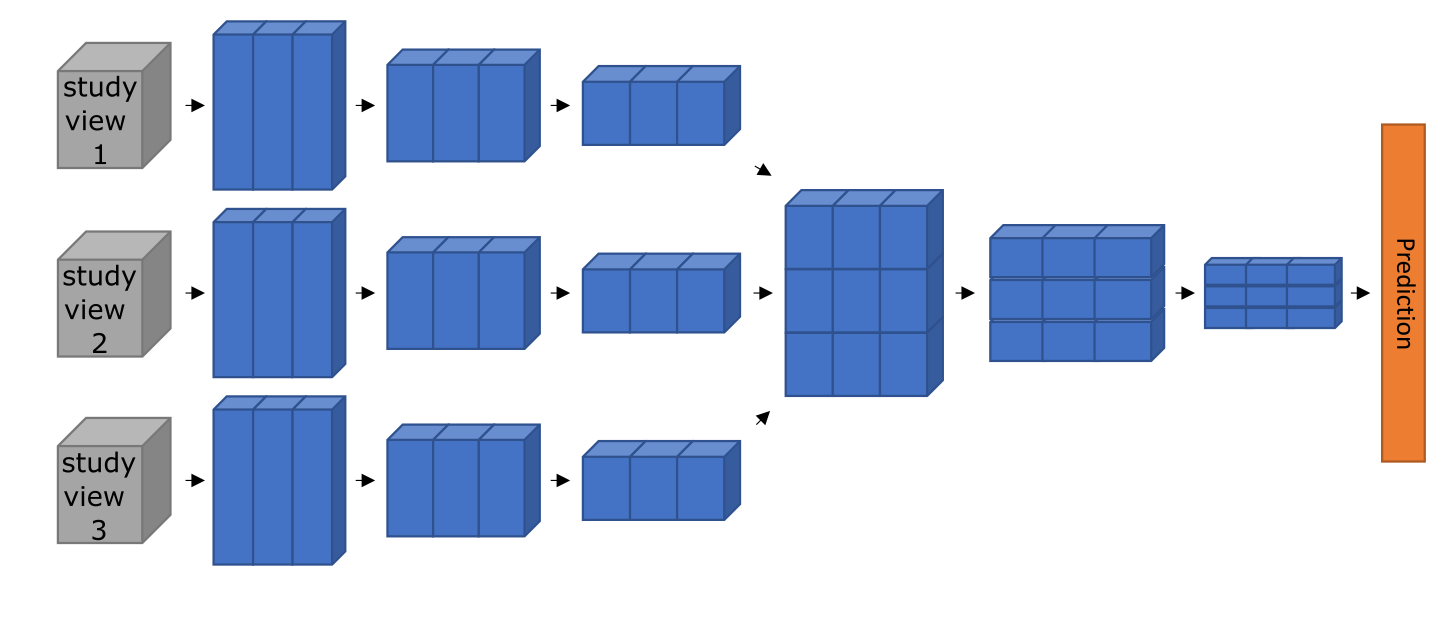
We applied the multi-view neural network architecture to several demonstration tasks in cardiac ultrasound, also called echocardiography. Echocardiography is the most common cardiovascular imaging modality and its interpretation regularly requires synthesis of complementary information across multiple views.
Each echocardiographic slice of the heart contains incomplete 2D information about the heart's 3D structure and function. By simultaneously accepting multiple views as input and integrating information across them, the multi-view neural network derives a more complete understanding of cardiac anatomy and function.
Our underlying multi-view neural network approach is applicable across the range of biomedical imaging applications: whenever multiple imaging views capture distinct but related information about the same underlying structure or process, learning across views within a single neural network may improve performance beyond analyzing views independently.
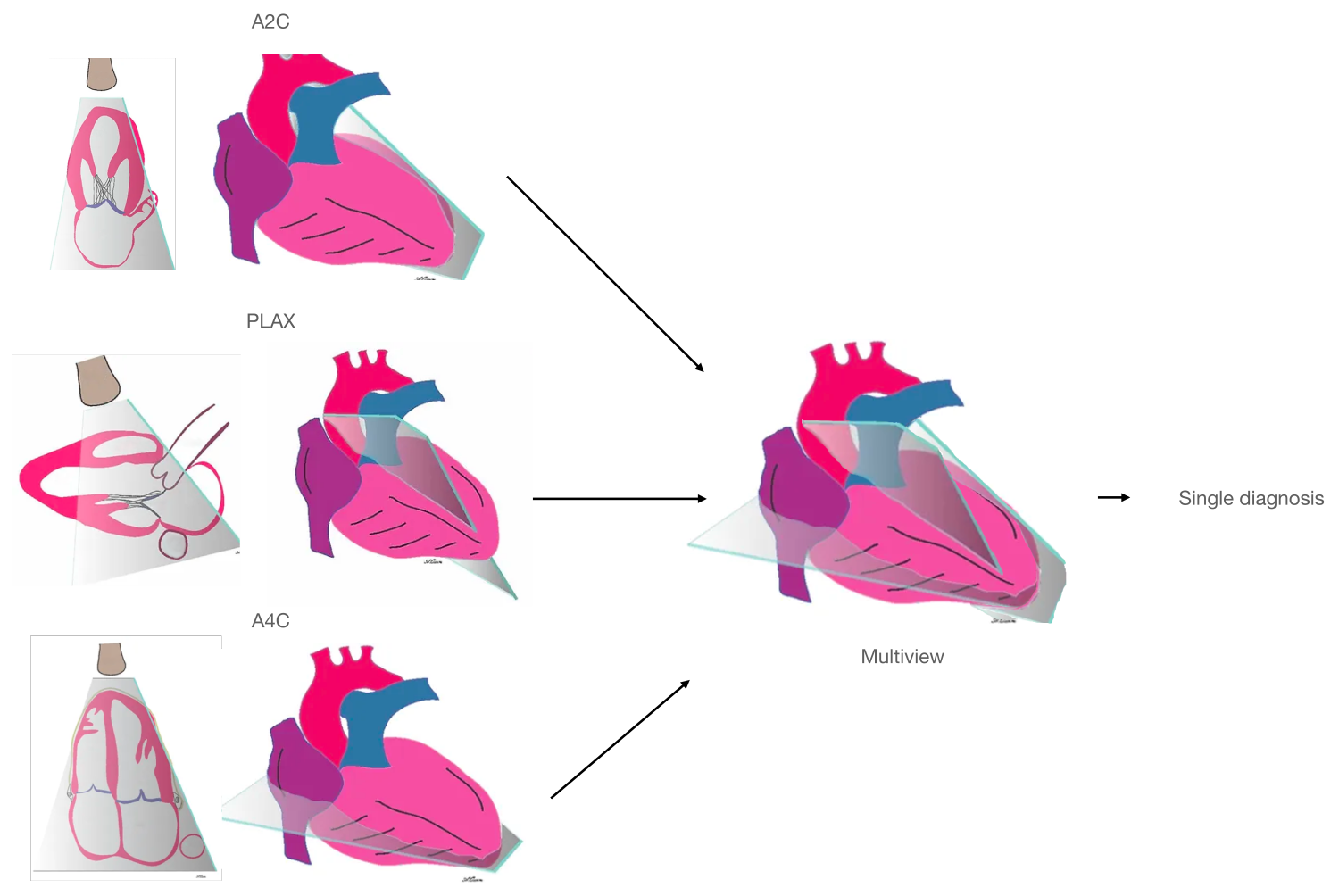
To illustrate the capabilities of the multi-view framework, we applied it to three representative diagnostic tasks in echocardiography:
- Detection of ventricular abnormalities
- Detection of diastolic dysfunction
- Detection of valvular regurgitation
These composite demonstration tasks were selected because they require integrating information from multiple views and reflect a mix of structural, functional, and flow-related assessments.
For each task, we compared three modeling strategies:
- A multi-view model that performs mid-fusion and convolutions across views
- Single-view models trained on individual views
- A late-fusion baseline consisting of the arithmetic average of the outputs from single-view models
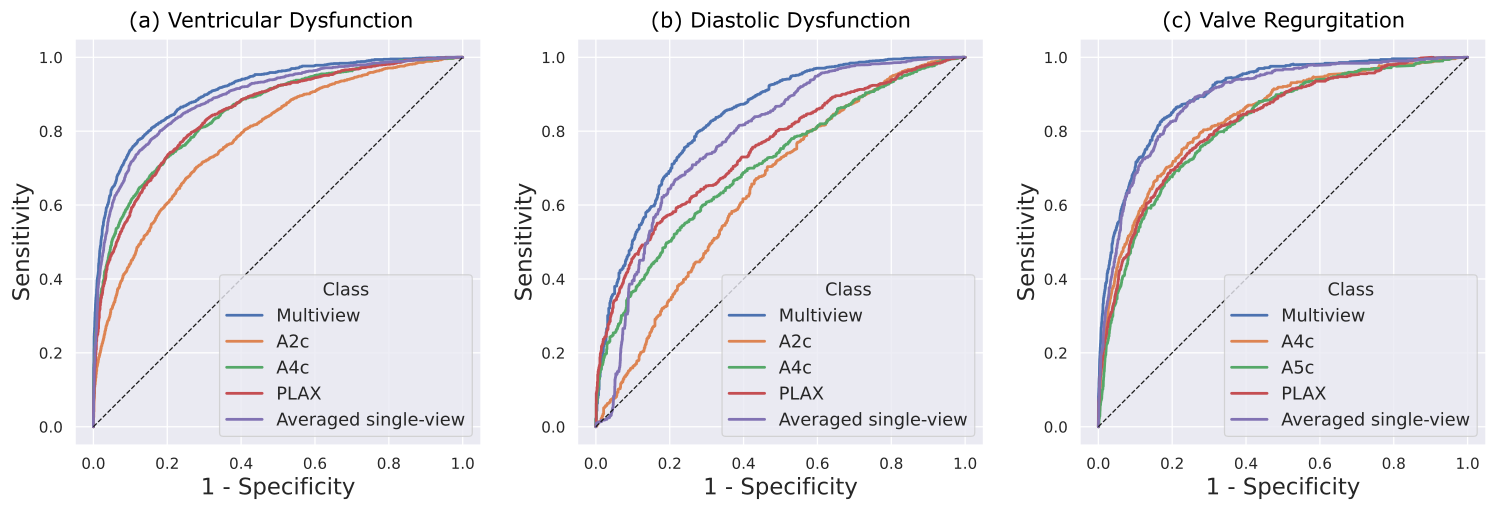
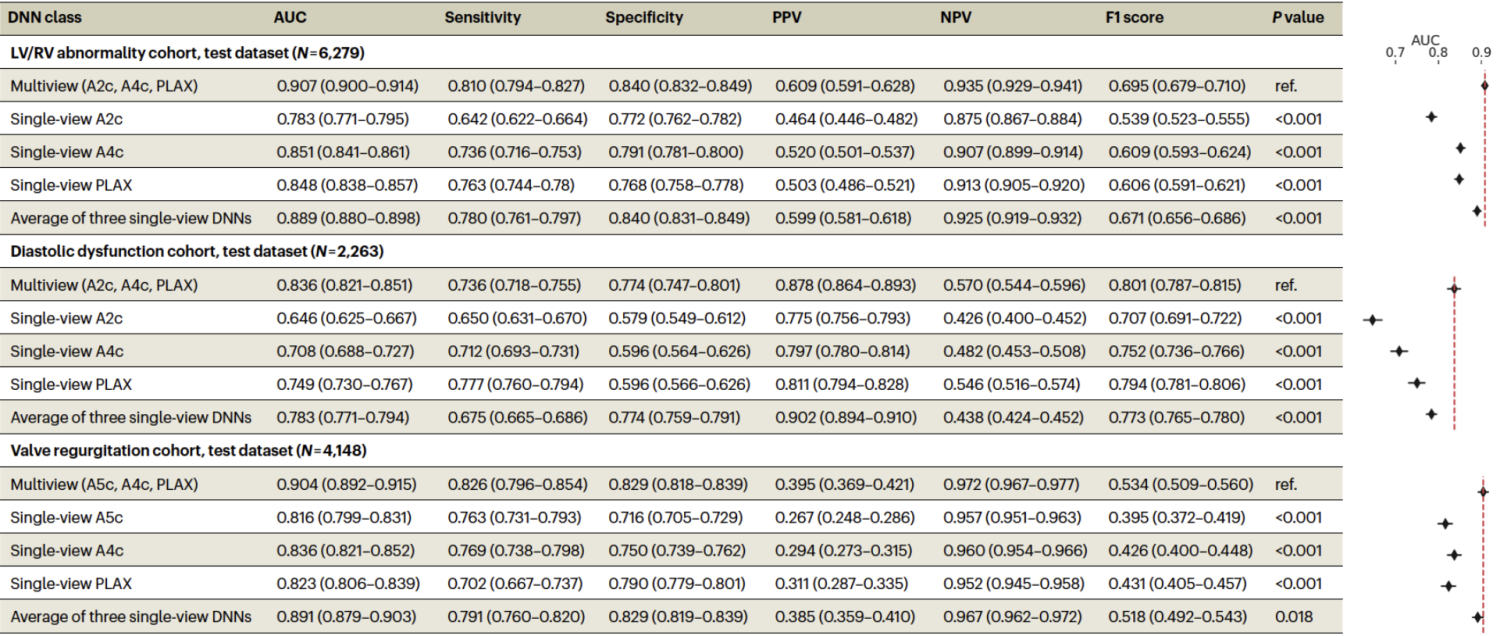
Across all three tasks, the multi-view framework demonstrated improved discrimination compared to single-view models. Performance gains also exceeded those achieved by late fusion, indicating that jointly learning across views provides additional benefit beyond ensembling independent predictions.
Importantly, these results suggest that explicitly modeling relationships between views can improve performance for tasks where diagnostically relevant information is captured across multiple distinct imaging views. While performance improvements provided by multi-view neural networks will likely depend on the target task, data availability, and view selection, these results support multi-view learning as a beneficial strategy for biomedical imaging applications.
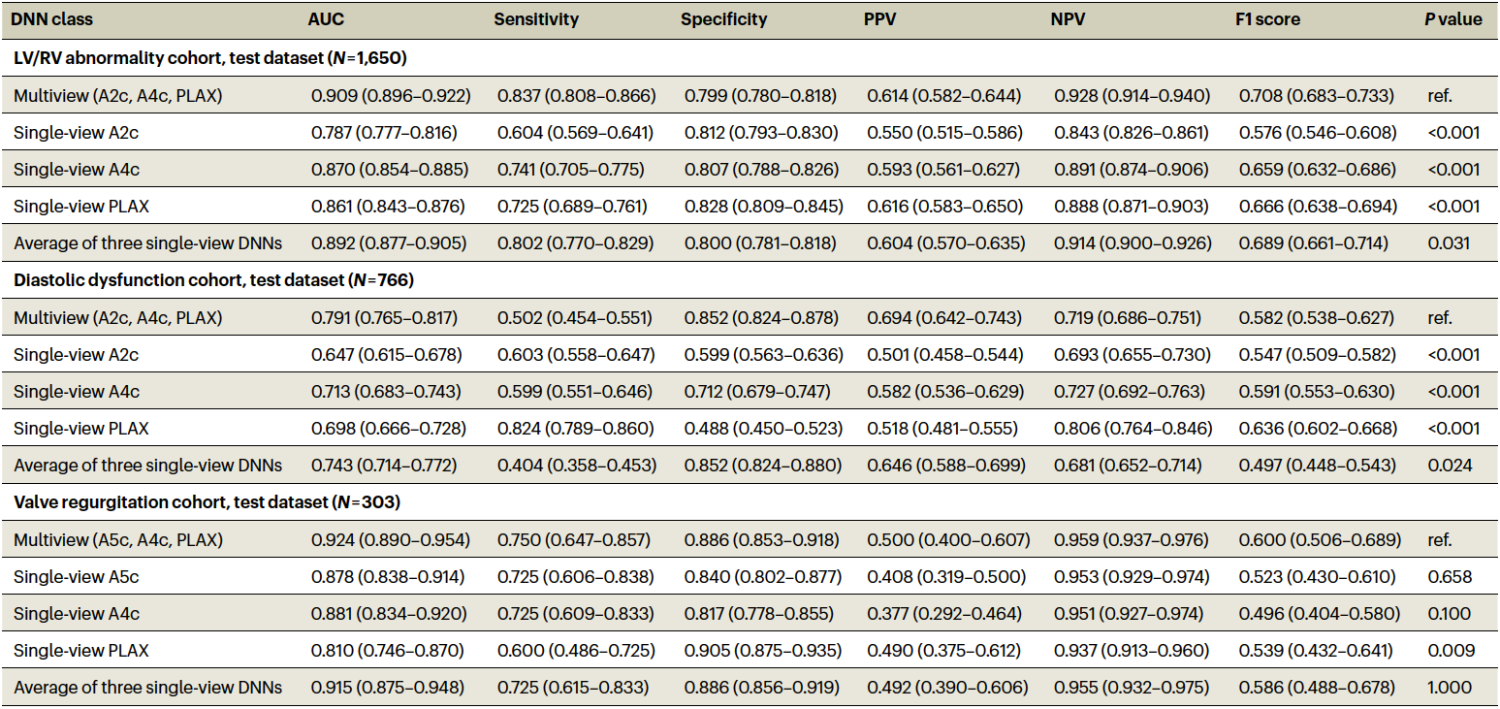
To assess generalizability, we evaluated the trained multi-view models on an external dataset acquired at the Montreal Heart Institute (MHI), Canada, using different equipment and measurement conventions. Despite these differences, performance was largely preserved.
These results suggest that our multi-view approach generalizes across hospital systems with differing demographics, acquisition devices, and practice patterns.
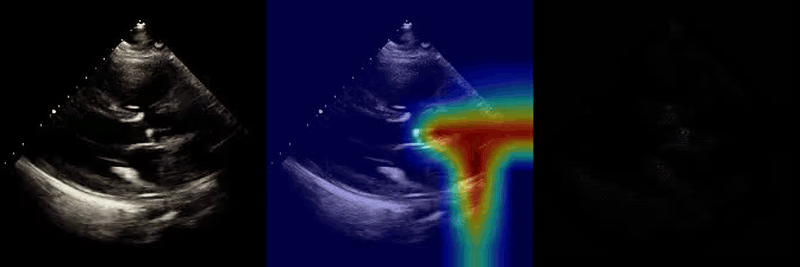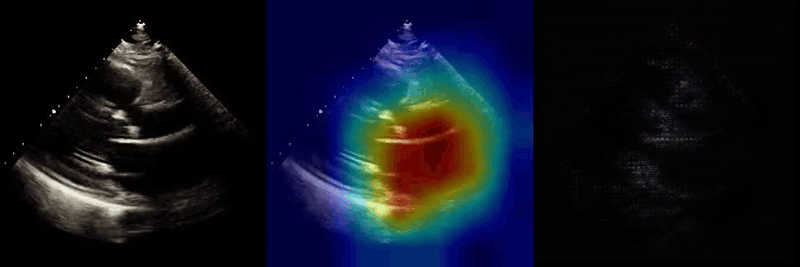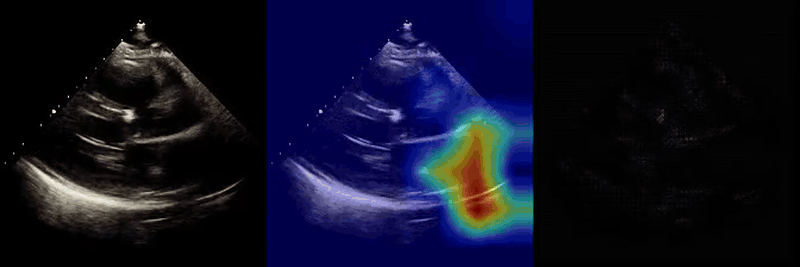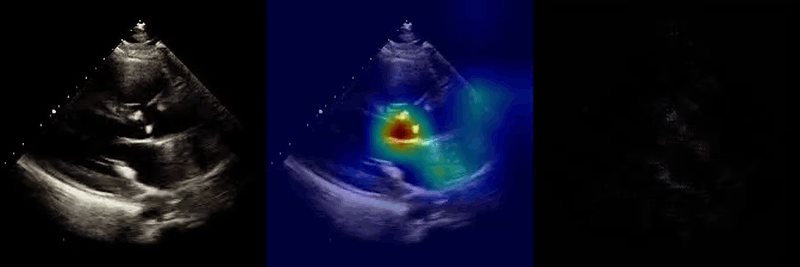
We used Grad-CAM and guided Grad-CAM techniques to visualize regions of the input videos that most strongly influenced model predictions. Across tasks and views, highlighted regions corresponded to anatomically and physiologically relevant structures, suggesting that the model learns meaningful features rather than relying on spurious cues.
This work demonstrates that a multi-view neural network architecture can integrate complementary video inputs to analyze complex three-dimensional structures, improving performance across a range of tasks and providing a general multi-view framework for other biomedical imaging applications.
Multi-view analysis of biomedical imaging videos may improve standardization and consistency in settings where diagnostically relevant information is distributed across multiple views or projections.
The proposed multi-view neural network approach improves performance on representative tasks and can be extended to other imaging modalities, tasks, and clinical domains.
Multi-view neural network architectures expand the capabilities of AI in biomedical imaging, laying the foundation to achieve augmented diagnosis and assisted decision support in diagnostic imaging.
Email questions or inquiries here.